What’s new in v1.13.0
🚀 Updates & Improvements🎙️ Voice Engine
Upgrades to TTS, realtime voice, and call performanceDynamic TTS Speed Control
You can now control TTS playback speed dynamically at runtime via commands. Speed values are validated before being applied, preventing out-of-range values from causing unexpected audio behavior.Deepgram TTS WebSocket Support
Deepgram TTS is now available over WebSocket, including full webcall integration. This improves reliability and reduces latency for Deepgram-powered voice playback.Advanced Voice Configurations
Support forgpt-realtime-1.5 has been added, along with exposed advanced realtime voice settings that were previously inaccessible. These settings allow fine-grained control over realtime voice behavior for assistants using OpenAI’s realtime API.Workflow Performance — Cache Pre-warming
Workflow-based assistant performance has been improved by pre-warming the workflow cache in the background at call creation time. This reduces cold-start latency on the first workflow invocation during a call.Hold Command Bug Fix
Fixed an issue with theplayAndBargein hold command that could cause incorrect call handling behavior when a hold was triggered during active playback.📞 Call Handling & Integrations
Twilio Inbound Callhook
New APIs for retrieving and binding Twilio inbound callhooks are now available. Minor updates have also been made to number management to support inbound callhook configuration.Twilio Signature Validation
Twilio request signature validation has been improved. Rejection of requests with invalid signatures has been temporarily disabled to ensure reliability during the rollout, while the validation logic itself is hardened.Note: Signature rejection will be re-enabled in a future release once validation is fully verified across all inbound traffic patterns.
Active Calls Query Optimization
The active calls query has been fully rewritten to avoid inefficient lookups. This improves performance for teams with a high volume of concurrent calls and reduces database load during peak traffic.📝 Transcripts & Reporting
Offline Call Transcripts
Call transcripts can now be uploaded to S3 after a call ends. This release also adds:- A dedicated transcript download API
- Improved Deepgram response parsing for more accurate transcript data
- A new assistant-level config for enabling post-call transcript generation
Conversation Analysis Enhancements
Two new analysis sections have been added to conversation analytics:- DND (Do Not Disturb) — surfaces DND signals detected during the call
- Callback — tracks callback intent and scheduling outcomes
Bug Fixes
- DND null check — Fixed a null reference error that could occur when a DND object was absent during a DND update operation
🔄 Workflow Service
Significant runtime improvements, new model support, and observability upgradesAnthropic Claude Model Support
Anthropic Claude models are now supported within the workflow framework alongside existing OpenAI and Azure models. Select a Claude model in your LLM node configuration to use it in any workflow.Workflow Node Builders
Pre-built node builders are now available for the following node types, reducing the boilerplate required to add common workflow steps:summary— summarize conversation contextsuccess— mark a workflow run as successfulstructured_data— extract structured output from an LLM responsednd— handle Do Not Disturb detectioncallback— schedule a callback action
Workflow Run Checkpointing
Workflow runs now support checkpointing and state reconstruction. If a run is interrupted, execution can be reconstructed from the last checkpoint rather than restarting from the beginning.Resume Workflows from Any Node
Workflows can now be resumed from any node with an initial state context provided at resume time. This enables retry and recovery flows without requiring a full restart.Workflow Cache Improvements
The workflow cache is now enabled by default. An internal endpoint for manual cache management has also been added for operational use.Redis Caching for Workflows
Redis caching for fully hydrated workflows has been implemented behind a feature flag (disabled by default). When enabled, this significantly reduces workflow load times for frequently-used workflows.In-Memory Workflow Handler
An in-memory workflow handler has been added behind a feature flag. This is intended for environments where low-latency execution is prioritized and external state persistence is managed separately.Evaluation Workflow Run Persistence
Evaluation workflow runs are now persisted to the workflow service, making it possible to review and compare evaluation results over time.Debug Mode Observability
Debug mode now captures individual LLM metrics per node execution, giving developers per-node visibility into model latency and token usage during a workflow run.OpenAI Realtime Support
Support forgpt-realtime-1.5 has been added to the workflow service, along with dynamic Realtime API configuration. This aligns the workflow runtime with the voice engine’s realtime capabilities.Fixes & Dependency Updates
- Fixed timezone expectation handling in workflow execution
- Fixed empty-messages edge case that could cause unexpected LLM behavior
- Improved credential redaction in workflow logs to prevent accidental secret exposure
- Updated dependencies for in-memory workflow runtime:
beanie,langchain,boto3
📣 Conversation & Campaigns
Twilio Throughput Limit
A Twilio throughput limit of 75 MPS has been implemented for sending campaign pre-call messages. This prevents campaigns from exceeding Twilio’s rate limits and causing message delivery failures at scale.Athena Appointment Rescheduling
Appointment rescheduling is now supported for Athena integrations. Assistants can handle rescheduling requests end-to-end through the EHR, in addition to the existing scheduling and cancellation flows.What’s new in v1.12.0
🚀 Updates & Improvements📣 Campaigns
Retry Mechanism
Full retry policy support is now available for campaigns. This includes:- Retry configuration models
- CRUD APIs for managing retry policies
- Retry logic for individual calls and bulk campaign execution
Contacts Management
A new contacts management module has been added to the campaigns service with dedicated CRUD APIs. Contacts can be created, listed, updated, and deleted independently of campaigns — making it easier to manage reusable contact lists across multiple campaigns.Call Filtering & Statistics
New API endpoints for filtering calls by outcome and retrieving campaign-level statistics are now available. Use these to build dashboards, slice data by outcome or status, and measure campaign performance.What’s new in v1.11.0
🚀 Updates & Improvements🔁 Workflow Enhancements
Major platform-level upgrades to the workflow engineThis release ships a large set of improvements to the workflow runtime, tooling, observability, and model support.Callback Scheduling
Workflows can now schedule future callbacks via a dedicated API endpoint with full validation. Dynamic variable handling has been extended to support callback scheduling flows, so you can defer execution to a future time without custom workarounds.ToolNode — Direct Tool Execution
A newToolNode node type lets you invoke tools directly within a workflow without routing through an LLM. This is useful for deterministic steps where you want predictable, low-latency execution without incurring an LLM call.GPT-5 & GPT-5.4+ Model Support
reasoning_effort levels. Token usage is tracked uniformly across all LLM providers.OpenAI Responses API
Native support for the OpenAI Responses API is now available with an explicit opt-in flag. Thereasoning_effort parameter is passed through for custom LLM configurations.External API Tool Enhancements
The external API calling tool has been significantly upgraded:- Native response types preserved — responses are no longer cast to string
- Explicit error propagation — errors surface to the workflow instead of being silently swallowed
- HTTP retry support — transient failures are automatically retried
- Dynamic argument substitution — LLM tool arguments can be injected into the URL path, query parameters, and request body
Liquid Template Expressions in Dynamic Variables
Advanced Dynamic Variables
Extended dynamic variable operations with predefined system-level variables, giving workflows access to runtime context such as timestamps, call identifiers, and team metadata.Granular Error Tolerance
Configure per-workflow and per-node error tolerance thresholds so that non-critical failures degrade gracefully instead of aborting the entire run.LLM Latency & Call Tracking
Aggregated LLM latency statistics and call count are now tracked across workflow runs, giving you detailed observability into model performance over time.Vendor Credential Caching
Vendor credentials are now cached using a Redis cache-aside pattern with secure fallback. Credentials are scoped perteam_id, so multi-tenant deployments remain isolated.Workflow Runtime Stability
Improved error handling prevents cascading failures when individual nodes encounter errors.Azure OpenAI Fix
Resolved a validation error triggered by a missingapi_version field in Azure OpenAI chat configurations.UI Ordering in System Prompt
Added UI ordering metadata and a special field type to system prompt configuration for workflow nodes, making it easier to organize and read complex prompt structures in the dashboard.💬 Conversations
Start Message on Tool Execution
When a non-interruptible music tool begins executing during a conversation, a start message now plays automatically. This provides callers with immediate audio feedback that the system is processing, reducing perceived silence.🔑 Vendor Credentials
TTS Playground Vendor Credential Support
The TTS playground now correctly uses vendor-level credentials when testing voices. This allows you to test provider-specific voices using your own credentials, rather than falling back to default platform credentials.Redis Cache Invalidation for Vendor Credentials
Vendor credential updates are now immediately propagated across the system via Redis cache invalidation. Previously, credential changes could take time to take effect due to stale cache entries.🛠️ Admin Tools
Webhook Logs
Admins can now view webhook activity logs directly in the dashboard. This provides improved observability into webhook delivery, making it easier to debug integrations and verify that events are being received correctly.🐛 Bug Fixes
Assistant Call History
Fixed persistence of assistant call history, including the conversation ID link and assistant phone number resolution. Call history entries were previously missing or incorrectly linked in some cases.What’s new in v1.7.0
🚀 Updates & Improvements🔐 Okta SSO Login Support
Enterprise Single Sign-On IntegrationWe’ve added support for Okta Single Sign-On (SSO), enabling seamless integration with enterprise identity providers. Okta SSO support is available for organizations that require enterprise authentication.Note: Okta SSO is not enabled by default. If you need SSO support for your organization, please contact our support team and we’ll enable it for you.
🎵 Hold-Call Tag Support
Pause Calls with Custom Hold MusicCustom LLM workflows can now trigger call holds with configurable hold music using the hold-call tag. This is useful for scenarios where you need to pause a call and play background music.How to Use
Add the following XML tag to your custom LLM response:Configuration Details
<hold_call/>- Triggers the hold state<play_type>- Type of hold music (e.g.,keyboard,music)<play_duration>- Duration in seconds to play hold audio
🔍 Search KB and Assistants by ID
Resource Discovery by Object IDOur dashboard portal now supports searching for knowledge bases, assistants, and workflows by their object IDs, in addition to existing search by name and description.Features
- Search by ID - Find resources directly using their unique object IDs
- Quick Navigation - Click search results to instantly navigate to the resource detail page
- Comprehensive Search - Combine ID-based search with name and description searches for maximum flexibility
🔄 Redis Retry Handling for Connection Failures
Improved Infrastructure ResilienceWe’ve enhanced our Redis connection handling to gracefully manage connection failures, particularly during cloud provider maintenance windows or temporary service interruptions with AWS Redis Cache and similar services.What’s Improved
- Automatic Retry Logic - Seamless recovery from temporary Redis connection failures
- Better Error Handling - Improved internal error management to prevent cascade failures
- Enhanced Stability - More reliable system operation during infrastructure maintenance
- Transparent Recovery - Automatic reconnection without manual intervention
Impact: This improvement reduces system errors and improves overall platform reliability during cloud provider maintenance windows and temporary outages.
📨 Webhook for Concurrency-Failed Call Events
Improved Event Delivery for Failed CallsWe’ve fixed webhook delivery for calls that exceed your organization’s concurrency limits. Previously,end-of-call-report and status-update webhooks were not delivered when calls hit concurrency limits.What’s Fixed
- Concurrency Limit Events - Webhooks are now delivered when calls fail due to concurrency limits
- Consistent Event Delivery - Both
end-of-call-reportand status-update events with failed status are now reliably delivered - Assistant-Level Configuration - Webhooks are sent to configured webhook servers at the assistant level
Pro Tip: Monitor concurrency failure webhooks to track and optimize your concurrency limits.
✅ Campaign Pre-Call Validations
Validate Calls Before Campaign LaunchA new field called “Validate Call Data Before Launch” has been added to campaign creation and update workflows. This enables you to validate all calls before your campaign goes live.How to Use
Enable call validation in your campaign settings:Benefits
- Quality Assurance - Catch invalid data before campaign execution
- Early Error Detection - Identify issues with phone numbers, formatting, and data integrity
- Webhook Notifications - Failed validations are reported to your configured webhook server
- Available Everywhere - Supported via both API and dashboard UI
Recommendation: Enable this feature to ensure campaign data quality and prevent execution delays.
⏰ Campaign Call Schedule Timing Overrides
Flexible Per-Call Schedule ConfigurationCampaign calls now support schedule timing overrides, allowing individual calls within a campaign to use different timezones and execution times than the overall campaign schedule.How to Use
Set override parameters per call during campaign upload:Example Scenario
Suppose your campaign is scheduled to run today and tomorrow from 9 AM to 6 PM:- Overall Schedule: Today & Tomorrow, 9 AM - 6 PM
- Override Example: Some calls run only today 3 PM - 5 PM
- Override Example: Other calls run only tomorrow 10 AM - 11 AM
Configuration Methods
- API - Using
override_timezoneandoverride_schedulefields - Dashboard UI - Campaign calls upload screen
🎙️ Campaign Assistants Overrides
Per-Call Assistant ConfigurationCampaign calls can now override specific assistant features, allowing you to customize assistant behavior (voice, welcome message, and other configurations) for individual calls within a campaign.Override Assistant Configuration
Partially override assistant settings for a specific call:Override Assistant Entirely
Completely replace the campaign assistant with a different permanent assistant:Priority Rules
- Both Fields Provided -
override_assistant_idtakes priority overoverride_assistant override_assistant_idOnly - Use a completely different assistantoverride_assistantOnly - Customize specific fields of the campaign assistant
Configuration
- API - Supported via API only
- UI - Coming in future releases
📊 Campaign Calls Metadata Tracing
Custom Metadata for Call TrackingCampaign calls now support custom metadata that you can use to track and correlate calls within your systems. Metadata can be configured during campaign call upload and is returned in webhook events.How to Use
Configure metadata during campaign call upload:Features
- Custom Tracking - Define any metadata key-value pairs for your use case
- Webhook Integration - Metadata is returned in all call-related webhooks
- Call Correlation - Use metadata to correlate calls with your internal systems
- API Only - Supported via API (
override_metadatafield)
🐛 Bug Fixes and Improvements
- Enhanced system stability and reliability across platform
- Improved error handling for edge cases
- Better performance optimization for large-scale operations
- UI/UX refinements for improved user experience
- Fixed various minor issues affecting call quality
What’s new in v1.6.0
🚀 Updates & Improvements📞 Campaign Call Validation Before Launch
Validate Calls Before Campaign ExecutionWe’ve introduced a new feature that allows you to validate campaign calls before the campaign is launched. Previously, validation occurred only after the campaign had been launched, but now you have the ability to validate calls beforehand, ensuring better quality control and error prevention.How to Use
Enable call validation via API by setting the newvalidateOnUpload field:Configuration Details
- Field Name:
validateOnUpload - Type:
Boolean - Default:
false - Available via: API
Pro Tip: Enabling
validateOnUpload helps catch invalid phone numbers, formatting issues, and other potential problems before your campaign goes live, saving time and improving campaign success rates.🎙️ Transcriber (STT) Fallback Support
Enhanced Speech-to-Text ReliabilityWe’ve added fallback support for transcribers (Speech-to-Text). You can now enable fallback transcribers to ensure continuous speech recognition even if the primary transcriber encounters issues.This enhancement provides:- Improved Reliability - Automatic failover to backup transcriber
- Uninterrupted Conversations - Seamless transition during transcription issues
- Better Call Quality - Reduced chances of missed or garbled transcriptions
🔊 Self-Hosted Deepgram Transcriber Support
New Self-Hosted STT OptionWe now support self-hosted Deepgram as a transcriber (STT) option, giving you more control over your speech-to-text infrastructure.Supported Models
Currently supported models:- Nova 2 - English language
- Nova 3 - English language
Coming Soon: We will be adding support for more models and additional languages in subsequent releases.
🤖 Gemini 3-Flash LLM Support
New LLM Model OptionWe’ve added support for Gemini 3-Flash as an LLM model option for your assistants. This new model provides:- Fast response generation
- High-quality conversational capabilities
- Cost-effective performance for real-time interactions
🛠️ Bug Fixes and Enhancements
- Resolved various issues affecting system stability and performance
- General improvements to call quality and user experience
- Enhanced error handling across the platform
- UI/UX refinements for better usability
What’s new in v1.3.0
🚀 Updates & Improvements🔧 External API Tools - Full HTTP Method Support
Enhanced API Integration CapabilitiesExternal API Tools now support all standard HTTP methods, providing complete flexibility for integrating with third-party services and APIs.What’s Changed
Before: OnlyPOST method was supported by default for External API Tools.Now: Full support for all HTTP methods:GET- Retrieve data from APIsPOST- Create new resourcesPUT- Update existing resources completelyPATCH- Partial updates to existing resourcesDELETE- Remove resources
How to Use
- Navigate to the Tools Section in your dashboard
- Create or edit an External API Tool
- Select your desired HTTP method from the dropdown
- Configure the tool parameters as needed
- Attach the tool to your assistant
📚 Knowledge Base Optimization
Improved Query Performance and Indexing- Enhanced Query Processing - Optimized algorithms for faster knowledge base searches and more accurate results
- Advanced Indexing - Improved indexing mechanisms that reduce response times and enhance search relevance
- Better Scalability - Enhanced performance for larger knowledge bases with more documents and data
🎤 ElevenLabs Configuration Enhancement
New Streaming Latency ControlWe’ve added granular control over ElevenLabs streaming optimization, giving you more precise control over the balance between quality and latency.New Configuration Field
Configuration Details
- Field Name:
optimizeStreamingLatency - Value Range:
0to4 - New Default:
0(previously managed internally with value3) - Configuration Methods:
- Dashboard UI toggle
- API configuration support
Latency Optimization Levels
0- Maximum quality, higher latency (recommended for most use cases)1-2- Balanced quality and latency3- Previous default - good balance4- Maximum speed, optimized for real-time interactions
Migration Note: Existing configurations will automatically use the new default value of
0. If you were relying on the previous behavior, you may want to set this to 3 to maintain the same performance characteristics.📊 Per-Turn Latency Metrics
Enhanced Performance MonitoringWe’ve introduced detailed per-turn latency metrics for both user and assistant interactions, providing unprecedented visibility into conversation performance.New Metrics Available
User Turn Metrics:- Audio Packets latency
- Voice Activity Detection (VAD) latency
- Speech-to-Text (STT) processing time
- Total user turn processing duration
- Large Language Model (LLM) response generation time
- Text-to-Speech (TTS) processing duration
- Total assistant response latency
Where to Find These Metrics
-
Debug Mode Dashboard
- Enable Debug mode from your profile or by clicking the Interactly.ai logo
- Click on individual user or assistant messages in Call Logs
- View detailed timing breakdowns for each interaction
-
Webhook Integration
- Available in webhook subscription
messageevents - Real-time access to latency data for your applications
- Perfect for monitoring and analytics systems
- Available in webhook subscription
Use Cases
- Performance Optimization - Identify bottlenecks in conversation flow
- Quality Monitoring - Track response times across different configurations
- Analytics Integration - Export timing data to your monitoring systems
- Debugging - Diagnose latency issues in real-time conversations
🛠️ Bug Fixes and Improvements
- Resolved minor issues affecting call stability and user experience
- Various UI/UX refinements for better user interaction
What’s new in v1.2.0
🚀 Updates & Improvements🔧 Stability Improvements
- Enhanced system reliability with comprehensive bug fixes and performance optimizations
- Resolved known issues that were impacting call quality and user experience
- Improved error handling and recovery mechanisms across the platform
🎨 UI Enhancements
- Refined user interface elements for better visual consistency and usability
- Updated component styling and layouts for improved user experience
- Enhanced accessibility features and responsive design improvements
🎙️ Noise Suppression Configuration Updates
⚠️ Breaking Changes - Assistant ConfigurationWe’ve improved the noise suppression configuration with a more comprehensive and flexible approach. The following fields are now removed:noiseSuppressorConfig object:Configuration Options Explained
enabled- Master toggle for noise suppression functionalitysuppressBackgroundNoise- Controls Multi-Variate Noise Suppression (MVNS) to filter out ambient soundssuppressBackgroundVoice- Controls Background Voice Suppression (BVS) to minimize interference from other speakersdigitalGainControl- Controls Digital Gain Control (DGC) for automatic volume adjustmentknobValue- Fine-tune suppression intensity from 0 (minimal) to 100 (maximum)
Migration Guide
Before:Migration Required: Please update your assistant configurations to use the new
noiseSuppressorConfig object. The deprecated fields will continue to work temporarily but will be removed in a future release.🛠️ General
- Performance improvements and system optimizations
- Enhanced logging and monitoring capabilities
- Security updates and compliance improvements
What’s new in v1.1.0
🚀 Updates & Improvements📞 Caller ID Fix for Outbound Forwarded Calls
When an assistant‐initiated outbound call is forwarded to another recipient, the user caller ID (user’s phone number) is now preserved. The receiving user will no longer see the forwarded assistant’s caller ID.🎨 UI Enhancements
- Call Logs: Error Commands/Utterances are now visually highlighted in red for quick identification.
- Customer Logs: Updated layout and improved readability for streamlined troubleshooting.
- Assistant STT Configuration: UI support added for Deepgram Flux model configuration.
🗣️ Assistant Behavior Enhancements
- Added support for
<nonInterruptible>tag to ensure uninterrupted prompt/audio playback by the assistant. - Webhook listeners now emit LLM error events, allowing better error tracking and observability.
📚 Knowledge Base
- Pagination and search capabilities added within the assistant’s Knowledge Base for faster navigation and scaling with larger datasets.
🔄 Integration & Automation
- Support added to run cadence flow using Microsoft integration.
📘 API Docs Optimizations
- Improved API documentation layout and navigation for easier reference.
- Certain API URLs have been updated to new paths. If you have bookmarked API endpoints, please review and update them accordingly.
🛠️ General
- Multiple bug fixes and performance improvements across the platform.
What’s new in v1.0.0
1. Enable Debug mode (see Enable Debug mode section below)
Quickly turn on verbose developer logs from your profile so you can inspect detailed runtime information when diagnosing issues. When Debug mode is enabled the dashboard surfaces expanded logs and error traces useful for developers during troubleshooting.See the Enable Debug mode section below for more details.2. TTS — new audio cache scopes (assistant & team) + clip deletion
We added two new cache scope levels for TTS audio clips — assistant and team — so generated audio can be cached at the most appropriate scope for reuse and cost savings. The dashboard now also exposes the ability to delete existing audio clips so you can manage storage and refresh voices or content when needed.3. Campaign Webhooks
You can now register webhooks to receive real-time notifications for important campaign lifecycle events (for example: campaign completion) and per-call status updates (for example: call completed, failed, or dropped). Webhooks may be configured when creating or updating a campaign, enabling easy integration with downstream systems and automation pipelines.4. Twilio SMS — Inbound & Outbound
Dashboard toggle to enable Twilio SMS inbound and outbound functionality. This makes two-way SMS possible so your flows can receive replies and send messages via Twilio directly from the dashboard — useful for bi-directional support and conversational workflows.5. Vonage Number management
Buy or import Vonage phone numbers directly from the dashboard. Note: you will need to provide your Vonage credentials when adding or importing numbers.6. Fixed: missed tool calls and trailing messages
Resolved a bug where tool calls and messages at the end of conversations could be missed or dropped. This fix improves reliability for trailing-message flows and integrations that depend on final tool outputs.7. Stability & performance improvements
General reliability and performance upgrades across the platform — faster page loads, reduced error rates, and smoother dashboard interactions.Enable Debug mode
Debug mode helps developers view detailed diagnostic logs and metadata for conversations, making it easier to analyze performance, latency, and behavior of both Assistant and User utterances.How to enable Debug mode
You can enable Debug mode in two ways:-
From the logo — Click the Interactly.ai logo at the top-left corner.
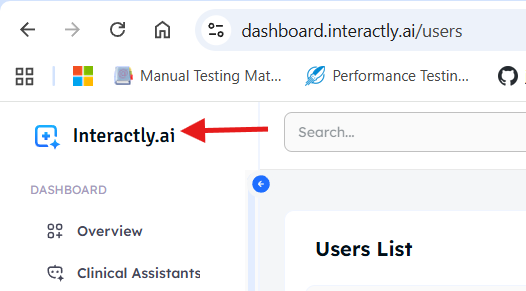
-
From your profile — Click the Profile icon at the top-right and toggle Debug mode ON.
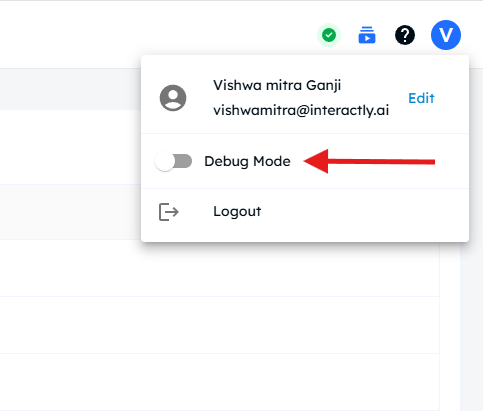
Debug info in Call Logs
Open any conversation from Call Logs after enabling Debug mode. You’ll notice new metrics displayed at each Assistant and User utterance.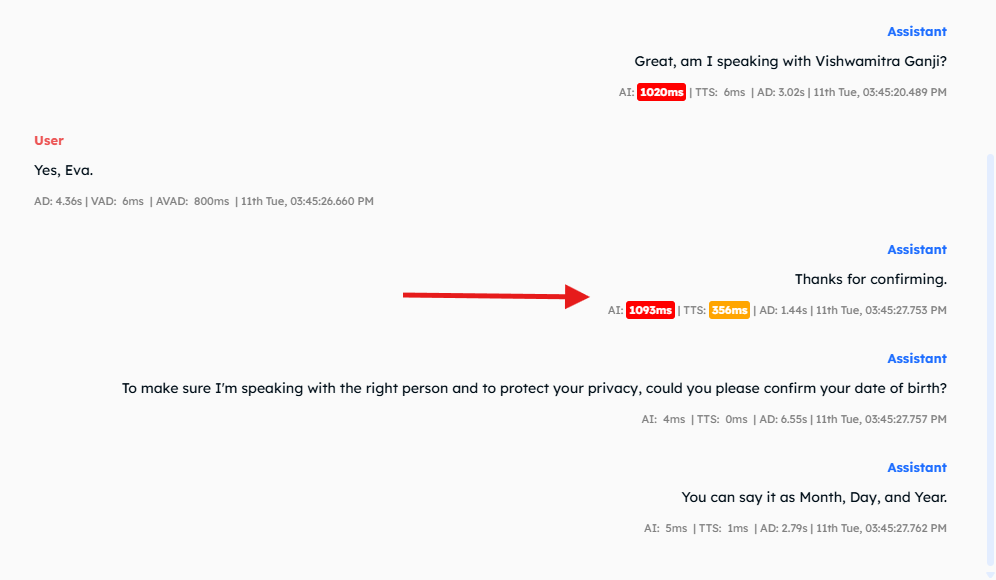
Assistant utterance metrics
- AI: 1093 ms — Time taken by the LLM to generate the response.
- TTS: 356 ms — Time taken by the TTS engine to generate the audio clip.
- AD — Audio Duration of that particular clip.
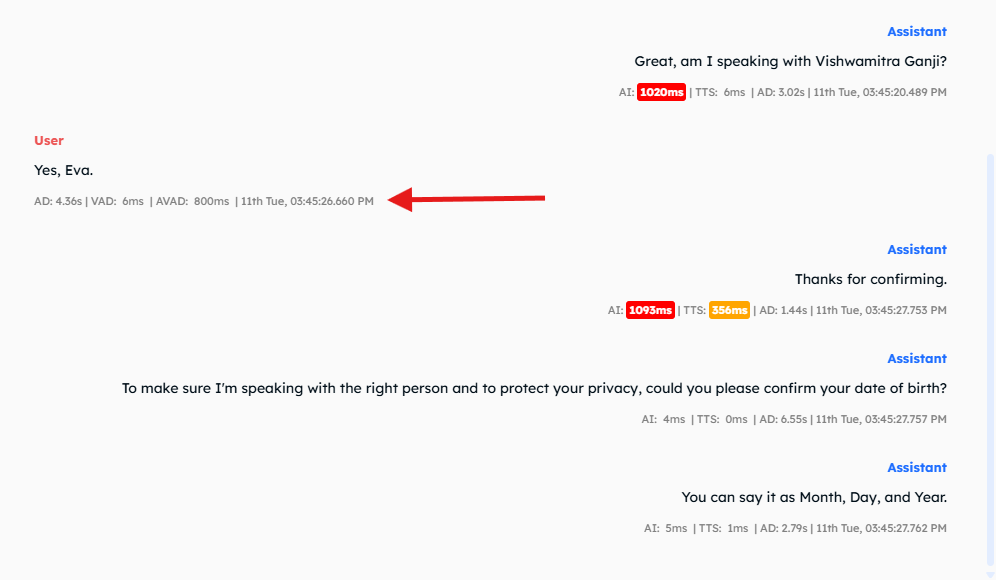
User utterance metrics
- AD — Audio Duration of the user’s spoken input.
- VAD: 6 ms (Voice Activity Detection) — Time the STT vendor waited after receiving the final word.
-
AVAD: 800 ms (Additional Voice Activity Detection) — Extra waiting time configured at the Assistant level under
Advanced → Start Speaking Plan → Smart Endpointing OFF.
Accessing Meta Info — Assistant utterances
To view detailed metadata, click on the Assistant key in the utterance view.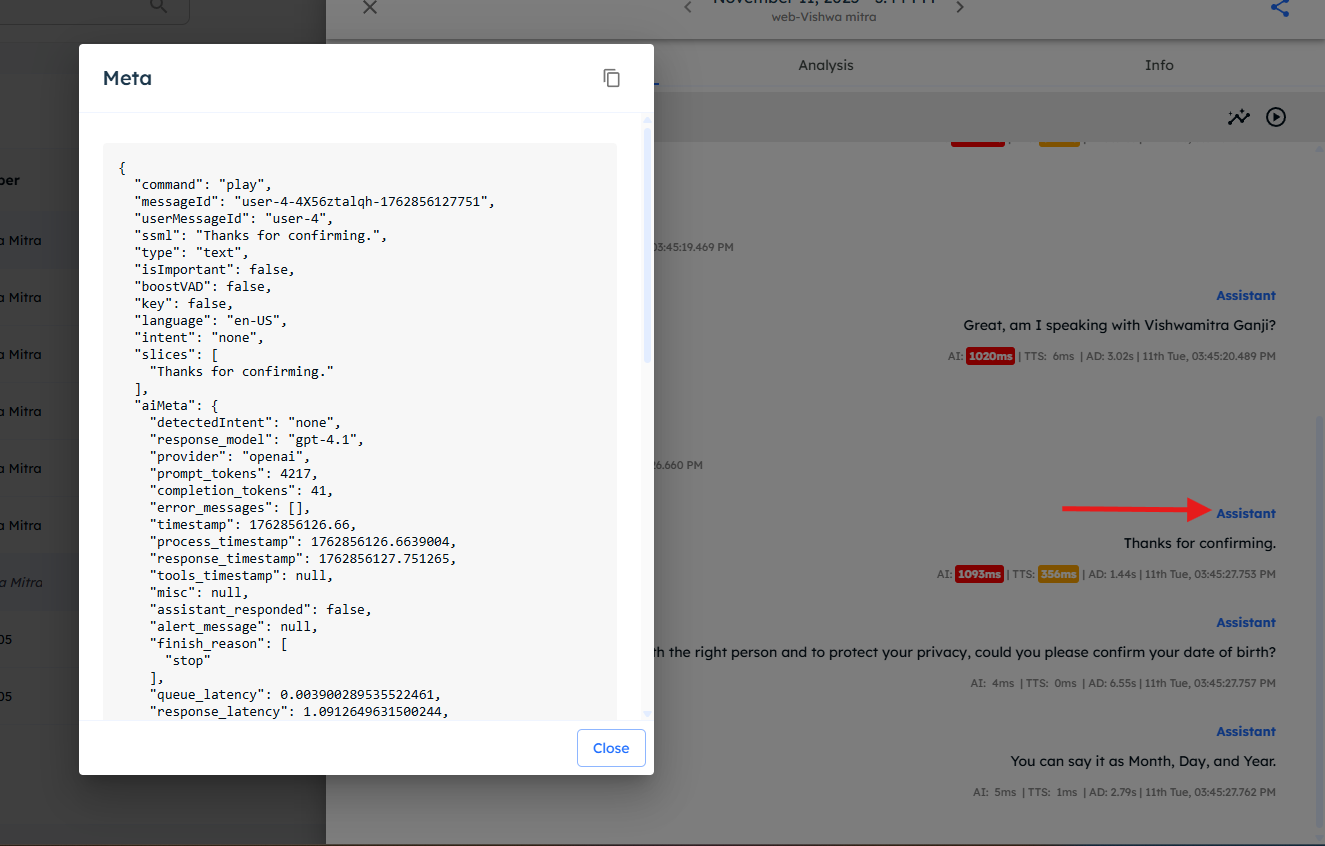
Key fields in meta info
-
command — Indicates whether the action is
PlayorEnd.Endsignals the call termination.
- messageId — Unique ID for the Assistant’s utterance.
- userMessageId — The ID of the corresponding user message that triggered this response.
AI Meta fields
-
finish_reason — Can be
stop,tool_calls, orlength.stop: Response finished naturally.length: Token limit reached.tool_calls: Model triggered a tool/function.
- queue_latency — Time the request waited before model processing started.
- response_latency — Time the model took to generate the response.
- trailing_messages — Last 6 utterances passed to the LLM for context.
Other useful fields
- audioDuration — Duration of the generated audio clip.
- isBargein — Whether the utterance was interrupted.
- isCachePlaying —
true/false; indicates if the clip was played from cache or generated fresh. - model / vendor — The TTS model and vendor used.
Accessing Meta Info — User utterances
Click on the User key in the utterance to view metadata for the user’s input.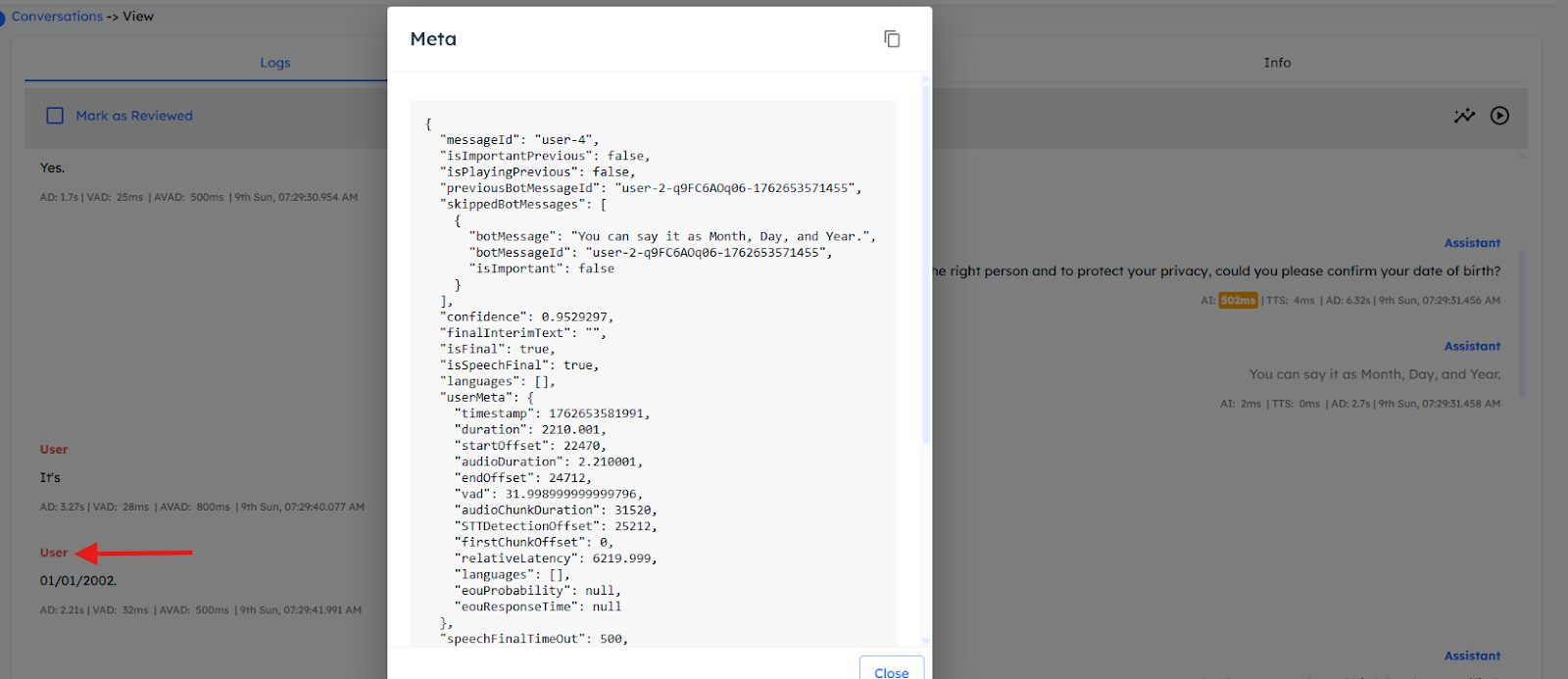
Important fields
- messageId — ID of the user message.
- previousBotMessageId — ID of the last Assistant response before this message.
- skippedBotMessages — List of interrupted Assistant messages skipped due to this utterance.
- confidence — Confidence score returned by the STT engine for this transcript.